Kra12cc

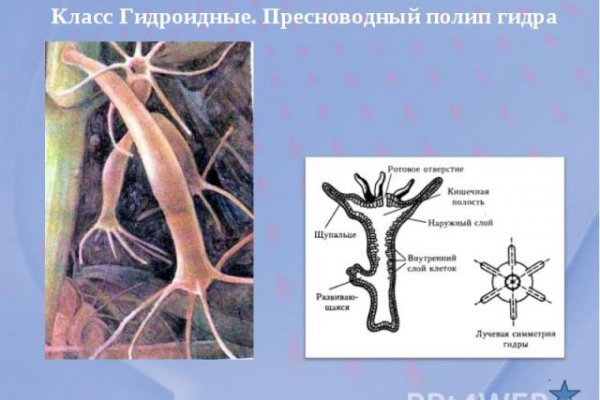
Сайт пользуется особой популярностью в даркнете, кракен где предлагаются к покупке запрещенные вещества, препараты, а также есть услуги программистов по взлому аккаунтов, почты. Главная страница Solaris Также отмечается, что в декабре прошлого года украинский ИБ-специалист Алекс Холден заявил, что ему удалось взломать Solaris и похитить 25 000 долларов, которые он затем пожертвовал украинской гуманитарной организации. Техподдержка работает без выходных и перерыва. Скачивание TorNado Browser осуществляется через App Store. Компания не собирается подставлять своих клиентов, потому что репутация для них дороже всего. ИБ-специалисты сообщают, крупный маркетплейс Solaris, специализирующийся на продаже наркотиков и других запрещенных веществ, был захвачен более мелким конкурентом, известным под названием Kraken. Но лучше всего заходить через браузер ТОР. На сайте представлен широкий выбор запрещенной продукции, которую просто так не получится купить в обычном интернете. Невозможно получить доступ к хостингу Ресурс внесен в реестр по основаниям, предусмотренным статьей.1 Федерального закона от 149-ФЗ, по требованию Роскомнадзора -1257. В настройках пользователь также может внести корректировки в логин и пароль. За счет этого невозможно узнать, под каким IP-адресом заходит тот или иной пользователь. Исследователи полагают, что за всем этим вряд ли стоят политические причины, скорее дело в финансах, а также «рыночных» интересах разных группировок. Браузер пользуется тремя ступенями шифрования данных, поэтому трафик не видит никто, включая провайдера и правоохранительные органы. Благодаря этому сайт гарантирует высокую скорость и минимальное время отклика. И вход осуществляется с помощью браузера ТОР. Это значит, что у сайта одна из лучших репутаций в сфере безопасности и пользоваться ресурсом могут все желающие. Принцип работы Tor основывается на функциональных возможностях сети Tor, которая работает во всем мире. Для начала использования нужно скачать браузер по ссылке. Для решения этой проблем проще всего воспользоваться зеркалом. После этого появится сам сайт, где можно совершать покупки. Для установки браузера на смартфон, который работает на Android, браузер нужно будет скачать с Play Market. Как теперь сообщают журналисты, в прошлую пятницу, года, представители Kraken объявили, что они захватили инфраструктуру Solaris, репозиторий торговой площадки на GitLab и все исходные коды проекта, благодаря «нескольким огромным ошибкам в коде». Помимо этого предусмотрены вкладки «Товары» и «Магазины». Использование браузера ТОР на Android и iOS. И благодаря такому браузеру любой желающий получает доступ к магазину Solaris com, где можно покупать все. Это точная такая же ссылка на сайт, но слегка с измененным префиксом или окончанием. Зеркало это своего рода запасной домен на тот случай, если первый не работает или попал под блокировку со стороны властей. Войти. Скидки стали первым инструментом в конкурентной борьбе. Он представляет собой студенистую полупрозрачную трубку длиной до. Какие социальные и экономические сдвиги вызвало закрытие «Гидры к чему они могут привести и как это скажется на жизни простых россиян в материале «Ленты. Так, исходник THC-Hydra.4 скачивается командой: wget m/vanhauser-thc/thc-hydra/archive/v8.4.tar. «Это мероприятие заняло у нас 3 дня без всякой спешки, и мы скачали абсолютно ВСЁ, что положено в таких случаях (и нас никто не остановил пишут представители Kraken. Андрей Голов, «Код безопасности В многополярном мире мы могли бы создать киберальянсы Безопасность Но, в отличие от «Гидры UniCC закрылся не из-за действий властей.
Kra12cc - Как войти на кракен
Информацию об акциях и скидках на уточняйте на нашем сайте. Нужно по индивидуальным размерам? Главное зеркало сайта. Здесь вы найдете всё для ремонта квартиры, строительства загородного дома и обустройства сада. Данные приводились Flashpoint и Chainalysis. Вывод! В Москве. Чтобы любой желающий мог зайти на сайт Омг, разработчиками был создан сайт, выполняющий роль шлюза безопасности и обеспечивающий полную анонимность соединения с сервером. Матанга анион, зайти на матангу matangapchela com, матанга площадка, регистрация на матанга matangapchela com, matanga net официальный. Для того чтобы войти на рынок ОМГ ОМГ есть несколько способов. 5 Примечания. Если же данная ссылка будет заблокированная, то вы всегда можете использовать приватные мосты от The Tor Project, который с абсолютной точностью обойдет блокировку в любой стране. И от 7 дней. Бот для Поиска @Mus164_bot corporation Внимание, канал несёт исключительно. Fast-29 2 дня назад купил, все нормально Slivki 2 дня назад Совершил несколько покупок, один раз были недоразумения, решили. Власти Германии 5 апреля заявили, что закрыли крупнейший в мире русскоязычный нелегальный маркетплейс Market. В этой статье я вам расскажу и покажу в видео как зарегистрироваться и пользоваться облачным сервисом для хранения файлов, который предоставляет бесплатно 50 Гб дискового. Перейти на БОТ! Аналоги капс. Топовые семена конопли здесь! 37 вопросов по теме «Гидра». Он превосходит мелкие-маркетплейсы, где часто многие кнопки и инструменты попросту не работают. Одним из самых простых способов войти в Мегу это использовать браузер Тор. Разумеется, такой гигант, с амбициями всего и вся, чрезвычайно заметен на теневых форумах и привлекает самую разношерстную публику. Всем привет, в этой статье я расскажу вам о проекте ТОП уровня defi, у которого. Мега сеть российских семейных торговых центров, управляемая. Это не полный список кидал! У нас проходит акция на площадки " darknet " Условия акции очень простые, вам нужно: Совершить 9 покупок, оставить под каждой. Функционал и интерфейс подобные, что и на прежней торговой площадке. Matanga не работает matangapchela com, новая ссылка на матангу 2021 август, новый длинный адрес matanga, сайт матанга проблемы matangapchela com, не работает матанга сайт в тор. Ссылки на аналогичные сайты, как Гидра, где продают товары.
Kraken channel - даркнет рынок телеграм 10 594 subscribers Информационный канал теневого рынка кракен, вход - зеркалаонион. Представитель службы поддержки объяснил ForkLog, что существующие клиенты из РФ могут депонировать и выводить криптовалюты допустимый объем операций зависит от уровня KYC. По статье 228231 УК РФ штраф до 1 млн рублей и лишение свободы на срок до 10 лет. За две недели моего пребывания на моих глазах умерло около 20 человек. Рублей и тюремный срок до восьми лет. Onion - The Majestic Garden зарубежная торговая площадка в онион виде форума, открытая регистрация, много всяких плюшек в виде multisig, 2FA, существует уже пару лет. Адекватные админы. Был разгар майских праздников, когда я впервые в жизни проблевался переваренной кровью. Как уже писали ранее, на официальный сайтах даркнет можно было найти что угодно, но даже на самых крупных даркнет-маркетах, включая Гидру, была запрещена продажа оружия и таких явно аморальных вещей как заказные убийства. Подавляющее большинство объемов составляют сделки BTC/USD, BTC/EUR, ETH/ USD и ETH/EUR (около 75 суточного объема торгов Kraken). В этой статье перечислены некоторые из лучших темных веб-сайтов, которые вы можете безопасно посещать. Влили 4 порции крови, сделали массу унизительных исследований, включающих засовывание пальца в жопу и всякое такое, вставили два зонда через нос в желудок и отправили поспать. Без снимка. Вернее, он есть, но по умолчанию скрыт. Enter на клавиатуре. Фактически даркнет это часть интернета, сеть внутри сети, работающая по своим протоколам и алгоритмам. Избранные монеты После добавление монет в избранное, они появятся в окне торгового терминала в столбце "Список наблюдения". День я терпеливо лечился кетановом, 19-го понял, что всё. При покупке: если эта цена ниже последней рыночный цены, ваш лимитный ордер добавляется в стакан заявок. Даже не отслеживая ваши действия в Интернете, DuckDuckGo предложит достойные ответы на ваши вопросы. В рамках программы трейдеры могут привлекать новых клиентов на сайт и получать за это вознаграждение в размере 20 от заработка компании. Для продвинутых учетных записей требуется загрузка идентификационных данных, социального обеспечения и другой информации (в зависимости от локации). Спасибо! Из минусов: недоступен депозит и вывод через фиат такая возможность открывается только со второго уровня (Intermediate).